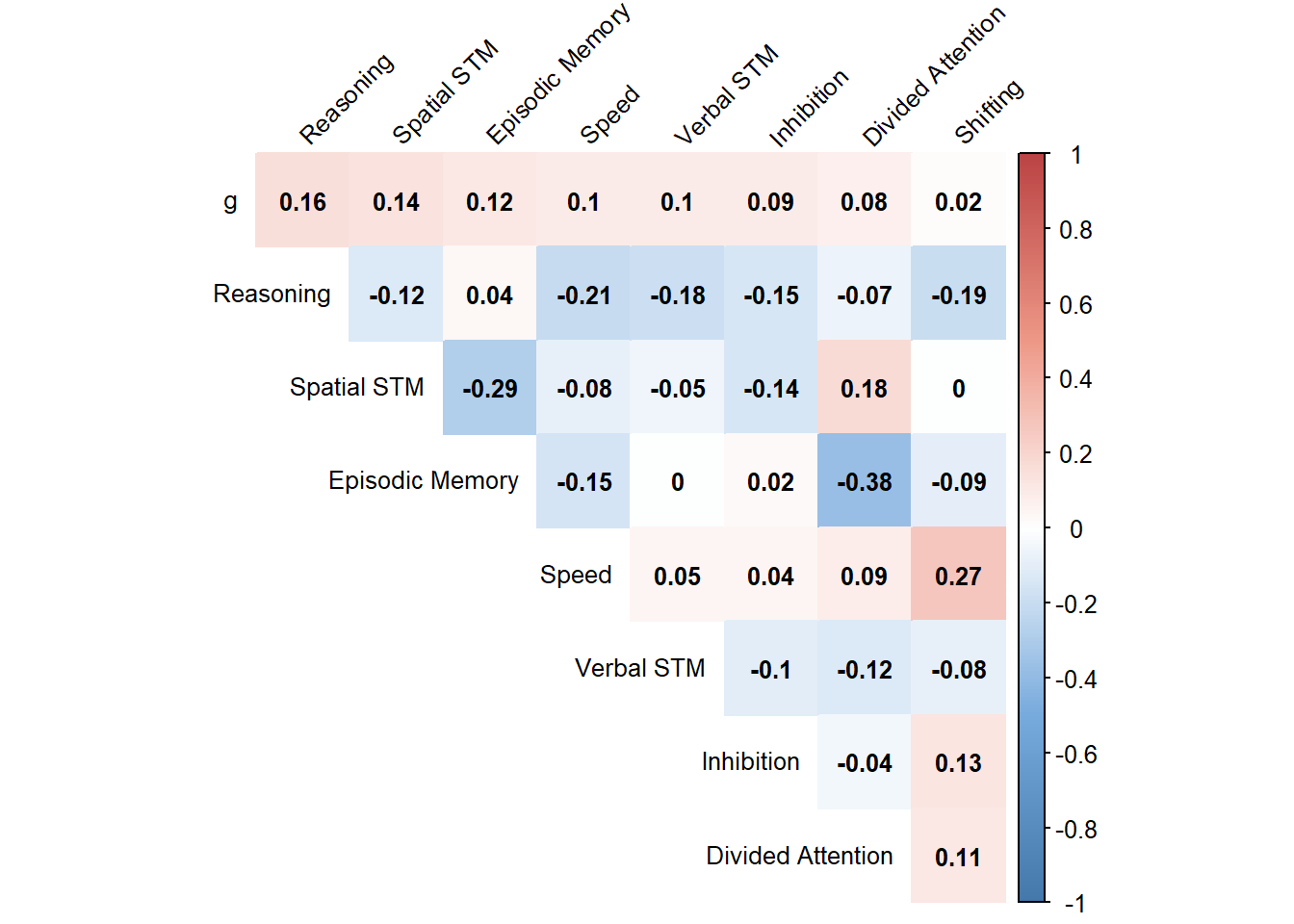
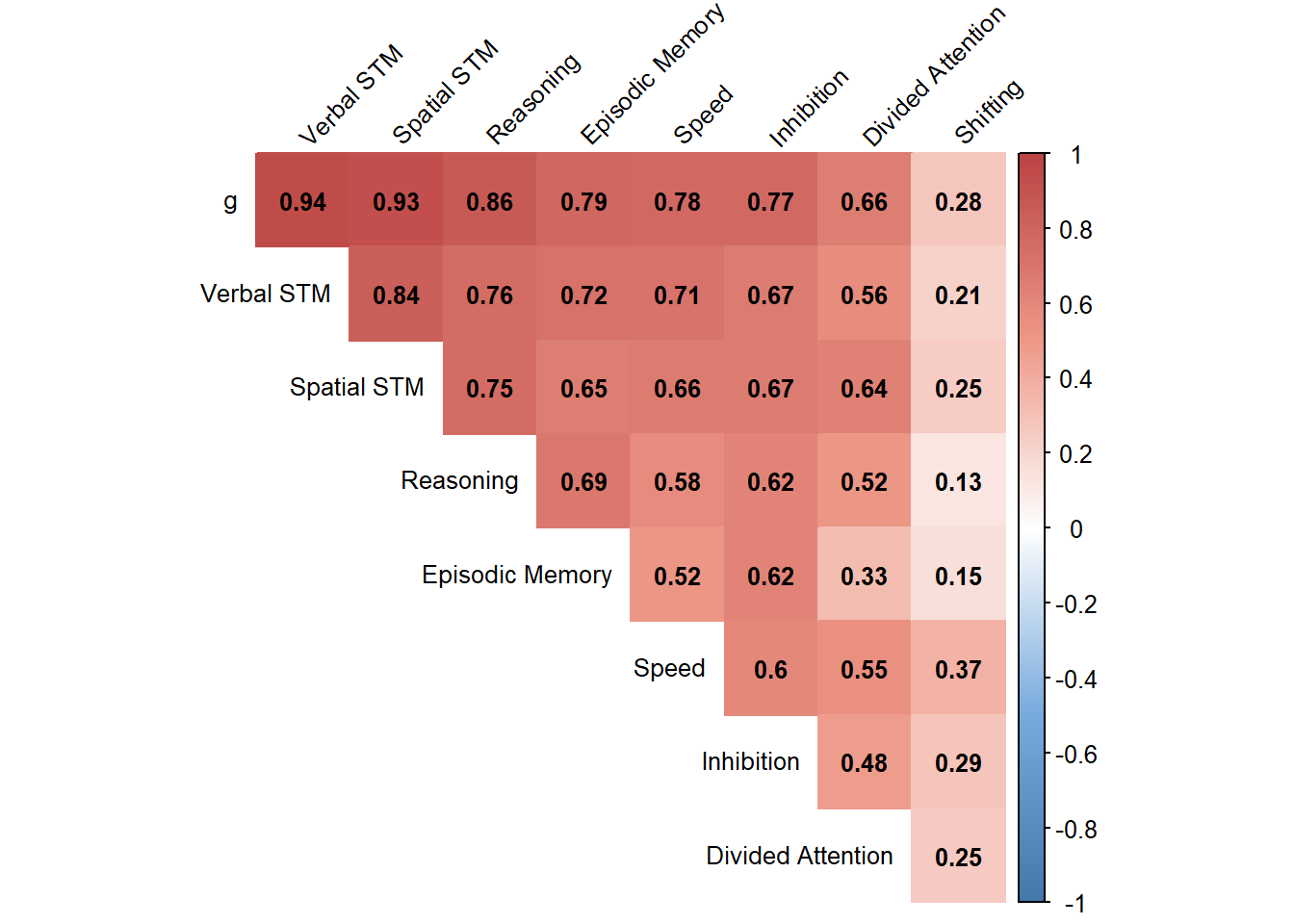
The correlation matrix by 2nd order model is more reasonable.
After excluding transfer domains ("Reasoning" and "Episodic Memory"), the most correlated 2 domains with g are "Spatial STM" and "Verbal STM". However, the correlation between them is also very high, which means that we should not include both of them as training domains. Here we include "Spatial STM" as the training domain 1. Two other selected training domains are "Divided Attention" and "Inhibition". Note that "Speed" is not selected as training domain because it is not so reasonable to be included as training domain 2.
As a reference, here we list the correlations with all latent factors for all tasks. (Rows with pink background are the transfer domains, rows with green background are the training domains.)
Code
corrs_task_dim |> gt::gt() |> gt::fmt_number(columns =c("g", all_of(names(dim_label_map))),decimals =2 ) |> gtExtras::gt_highlight_rows(rows = dim_name %in% dim_label_map[dim_transfer],fill ="#FFCCCC" ) |> gtExtras::gt_highlight_rows(rows = dim_name %in% dim_label_map[dim_train],fill ="#CCFFCC" ) |> gt::tab_header(title ="Task Selection Results",subtitle ="The most correlated task with g for each dimension/domain." ) |> gt::opt_interactive(use_filters =TRUE,use_highlight =TRUE )
Task Selection Results
The most correlated task with g for each dimension/domain.
Figure 1
Transfer Tasks
For reasoning, we used nonverbal reasoning task (see the highlighted row in Table 1).
For training tasks, we will consider the correlations with the training domain, the transfer tasks and g. The tasks should be most related to g, and the correlations between the training task and transfer task should also be matched.
But here comes the question of selecting single-domain training tasks. There are two options:
"Divided Atetion": this will match the mean correlations with g.
"Spatial STM": add this as additional group to further justify the effectiveness of multi-domain training (i.e., better than single-domain WM training).
Code
tasks_train <-c("蝴蝶照相机", "捉虫高级简版", "我是大厨")tasks_train_1 <-c("小狗回家", "一心二用PRO")tasks_train_1_alt <-c("打靶场", "位置记忆PRO")corr_task_transfer <- indices_of_interest |>inner_join(select(dims_origin, game_name, index_name, dim_label, dim_name),by =join_by(game_name, index_name) ) |>filter(!dim_label %in% dim_transfer) |>inner_join( indices_of_interest |>filter(game_name %in% tasks_transfer) |>pivot_wider(id_cols = user_id,names_from = game_name,values_from = score_adj ),by ="user_id" ) |>summarise(across(all_of(tasks_transfer),~cor(score_adj, .x, use ="pairwise.complete.obs") ),.by =c(game_name, index_name) )corrs_task_dim |>filter(dim_name %in% dim_label_map[dim_train]) |>left_join( corr_task_transfer,by =join_by(game_name, index_name) ) |>select( dim_name, game_name, g, SSTM, VSTM, Inh, AttDiv, Rsn, EM,all_of(tasks_transfer) ) |>arrange(desc(g)) |> gt::gt() |> gt::fmt_number(decimals =2) |> gtExtras::gt_highlight_rows(rows = game_name %in% tasks_train,fill ="#11FF11" ) |> gtExtras::gt_highlight_rows(rows = game_name %in% tasks_train_1,fill ="#88FF88" ) |> gtExtras::gt_highlight_rows(rows = game_name %in% tasks_train_1_alt,fill ="#CCFFCC" ) |> gt::tab_footnote(footnote =paste("Although '候鸟迁徙PRO' is most correlated with both g and Inhibition,","it is not selected because it is a multi-domain (`Inh` and `Shift`) task." ) |> gt::md(),locations = gt::cells_body(columns = game_name,rows = Inh ==max(Inh) ) ) |> gt::opt_footnote_marks("standard")
Table 2: The selected training tasks (train group). The rows with darker background are from three different domains, the rows with lighter background are single "Divided Atetion" tasks, and the rows with lightest background are single "Spatial STM" tasks.
dim_name
game_name
g
SSTM
VSTM
Inh
AttDiv
Rsn
EM
图形推理
万花筒
Spatial STM
蝴蝶照相机
0.69
0.81
0.62
0.50
0.51
0.51
0.42
0.35
0.28
Spatial STM
打靶场
0.62
0.71
0.57
0.42
0.42
0.47
0.44
0.31
0.23
Spatial STM
位置记忆PRO
0.59
0.74
0.52
0.37
0.46
0.44
0.32
0.27
0.18
Spatial STM
路径学习
0.53
0.62
0.44
0.38
0.31
0.47
0.44
0.34
0.29
Inhibition
候鸟迁徙PRO*
0.48
0.41
0.39
0.74
0.29
0.36
0.39
0.25
0.22
Spatial STM
萤火虫PRO
0.47
0.55
0.40
0.34
0.37
0.39
0.30
0.24
0.17
Divided Attention
我是大厨
0.42
0.39
0.36
0.31
0.59
0.31
0.25
0.23
0.17
Divided Attention
变戏法
0.40
0.36
0.34
0.33
0.61
0.29
0.20
0.21
0.11
Divided Attention
一心二用PRO
0.39
0.41
0.32
0.24
0.72
0.29
0.10
0.15
0.07
Inhibition
捉虫高级简版
0.39
0.30
0.30
0.64
0.20
0.33
0.33
0.29
0.16
Divided Attention
小狗回家
0.35
0.33
0.30
0.23
0.56
0.32
0.19
0.22
0.16
Inhibition
变色魔块PRO
0.29
0.23
0.24
0.47
0.23
0.16
0.22
0.13
0.12
Divided Attention
连点成画PRO
0.29
0.31
0.23
0.16
0.64
0.21
0.05
0.12
0.04
Inhibition
多彩文字PRO
0.24
0.21
0.20
0.41
0.13
0.15
0.19
0.11
0.11
Inhibition
数感
0.05
0.05
0.06
0.01
−0.01
0.05
0.07
0.08
0.06
* Although ‘候鸟迁徙PRO’ is most correlated with both g and Inhibition, it is not selected because it is a multi-domain (Inh and Shift) task.
Training Tasks (Active Control Group)
For this group, the domain least correlated with g, i.e., Shifting is selected. We choose the 3 most correlated tasks with Shifting as the training task.
Table 3: The selected training tasks (control group).
dim_name
game_name
g
Shift
Rsn
EM
图形推理
万花筒
Shifting
多变计数师
0.34
0.55
0.23
0.27
0.18
0.15
Shifting
卡片分类PRO
0.13
0.43
0.04
0.14
0.04
0.06
Shifting
察颜观色PRO
0.06
0.58
−0.02
0.00
−0.03
0.00
Shifting
候鸟迁徙PRO
0.06
0.54
−0.01
0.02
−0.02
0.02
Shifting
随机应变
0.05
0.60
−0.03
−0.07
−0.07
−0.03
References
Takeuchi, Hikaru, and Ryuta Kawashima. 2012. “Effects of Processing Speed Training on Cognitive Functions and Neural Systems.”Reviews in the Neurosciences 23 (3). https://doi.org/10.1515/revneuro-2012-0035.
Footnotes
Maybe spatial stimuli are better for younger children to understand and remember than verbal ones.↩︎